GenAI อย่าง Deepseek ราคาถูกแล้ว แต่ทุกอย่างจะถูกลงกว่านี้

GenAI และ LLM นั้นเป็นเทคโนโลยีที่ถูกพูดถึงตลอดในช่วงเวลานี้ และคงปฎิเสธไม่ได้ว่ามันเป็นตัวเร่งการใช้งาน AI อย่างรวดเร็วมากๆ ซึ่งความพยายามในการทำโมเดลภาษาขนาดใหญ่หรือ LLM นั้นมีมานานแล้ว แต่ยังไม่ได้สำเร็จง่ายๆ เพราะต้องใช้ข้อมูลในการสอนมหาศาล และมีข้อจำกัดทาง Hardware แต่เมื่อ Hardware นั้นพัฒนาขึ้นอย่างต่อเนื่องก็ทำให้การสร้าง LLM เป็นไปได้ขึ้นมา แต่ก็ตามมาด้วยราคาที่ค่อนข้างสูงเพราะต้องใช้ทรัพยากรจำนวนมากในการสร้าง และใช้งานด้วย – Sam Altman ตัว CEO ของ OpenAI ถึงขั้นเคยบอกว่าอย่าขอบคุณ AI เพราะมันเปลืองต้นทุนขึ้นด้วยเช่นกัน
ช่วงปลายปี 2024 DeepSeek เคยประกาศว่าตัวเองทำ LLM สำเร็จและยังใช้เงินแค่ประมาณ 6 ล้านเหรียญสหรัฐในการฝึกสอน model ตัว DeepSeek เมื่อเทียบกับ Facebook Llama 3.1 ที่ใช้เงินไปประมาณ 61 ล้านเหรียญ ทำให้หลายๆ คนตกใจและในมุมราคา Premium ของ GenAI ก็ดูจะเงียบๆ หายไป เพราะถูกกว่าบางครั้งอาจจะดีกว่าได้เหมือนกัน
โดยเราได้เห็นแนวคิดสองข้าง ฝั่งอเมริกาที่ดูจะเป็น Technology Leader จะเน้นไปที่ความสามารถที่มากขึ้น และเก่งขึ้นโดยไม่ได้กังวัลเรื่องการทำปรับปรุงประสิทธิภาพ (Optimization) เท่าไรนัก ให้อารมณ์เหมือนมีเงินเยอะมีทรัพยากรเยอะก็เน้นสร้างให้เก่งไปเลย ยังไม่ได้ต้องกังวลเรื่องต้นทุน เพราะโอกาสทางธุรกิจมันมีค่อนข้างสูง
และฝั่งประเทศที่อาจจะหาซื้อ Hardware ยากขึ้นอย่างประเทศจีน ก็มาโดยแนวที่เน้นการปรับปรุงประสิทธิภาพและสร้างโมเดลที่ขนาดไม่ต้องใหญ่แต่แก้ปัญหาใน Use Case จำเป็นๆ ได้ และดันเก่งไม่แพ้กับตัวแพงๆ ในกรณีงานทั่วไป และยังเปิดเป็น open-source เพื่อให้คนส่วนมากดาวน์โหลดไปใช้กันได้อย่างฟรีๆ ก็ถือว่าเป็นกลยุทธ์ที่ทำให้ฝั่งอเมริกาสะดุดอยู่เหมือนกัน ว่าต้องกลับมาคิดเรื่อง Optimization บ้างไหม
แต่อย่างใดก็ดีมีนักวิจัยจากมหาวิทยาลัย Stanford และ มหาวิทยาลัย Washington ออกมาโพสต์ในเดือนกุมภาพันธ์ 2025 ที่ผ่านมาว่าสามารถสร้าง S1 LLM ได้ในราคา $6 เหรียญสหรัฐ หรือในมุมมองเวลาคือ DeepSeek ใช้ 2.7 ล้านชั่วโมงในการสร้าง แต่ S1 ใช้แค่ 7 ชั่วโมงเท่านั้น ซึ่งตัว S1 กับ DeepSeek v3 ก็เทียบกันตรงๆ ไม่ได้ เพราะว่า DeepSeek V3 เป็นการสอนจากศูนย์เหมือน LLM ปกติ แต่ตัว S1 นั้นใช้วิธี fine-tuned บนตัว Qwen2.5 ของ Alibaba ดังนั้นก่อนที่ S1 จะเอามาใช้ต่อ ตัว Model นั้นสามารถตอบคำถาม หรือเขียนโค้ดได้บ้างอยู่แล้ว
ซึ่งการ Fine-tuning ปกติก็ไม่ได้ทำให้ราคาลดลงแบบนี้ได้ แต่ทางทีมฝั่ง S1 นั้นก็ยังได้สร้างเทคนิคใหม่ในการทำวิจัย AI โดยการตั้งสมมุติฐานว่า ข้อมูลขนาดเล็กๆ แต่คุณภาพสูงพอ จะทำงานได้ดีเหมือนกับการสอนแบบเดิมๆ โดยใช้ข้อมูลมหาศาลได้เช่นกัน เพื่อทดลองเค้าก็เลยเลือกคำถาม 59,000 ชุด ซึ่งรวมทุกอย่างตั้งแต่ข้อสอบภาษาอังกฤษระดับปริญญาโท คำถามในด้านสถิติ ด้วยความตั้งใจในการทำให้มันแคบที่สุดสำหรับชุดข้อมูลที่จะนำไปสอน AI ซึ่งแน่นอนว่าคำถามอย่างเดียวไม่พอ มันยังต้องการคำตอบไปสอนด้วย ทีม S1 เลยใช้ AI ตัวอื่นๆ เช่น Claude มาช่วยเรื่อง Cleansing หรือจัดกลุ่ม และอีกตัวซึ่งคือ Google Gemini ในการช่วยตอบคำถามแบบใช้ตรรกะ (Reasoning model) และให้กระบวนการคิด (thought process) ติดไปในชุดข้อมูลสำหรับสอนด้วย ดังนั้นจะมีข้อมูล 3 ชุด 1. คำถาม 59,000 ข้อ (เมื่อ Clean แล้วเหลือประมาณ 51,000), คำตอบ, และกระบวนการคิด (chains of thought) ในการเชื่อมทั้งสองเข้าด้วยกัน ถือเป็นเทคนิคที่ค่อนข้างตรงไปตรงมาแต่มีประสิทธิภาพมาก
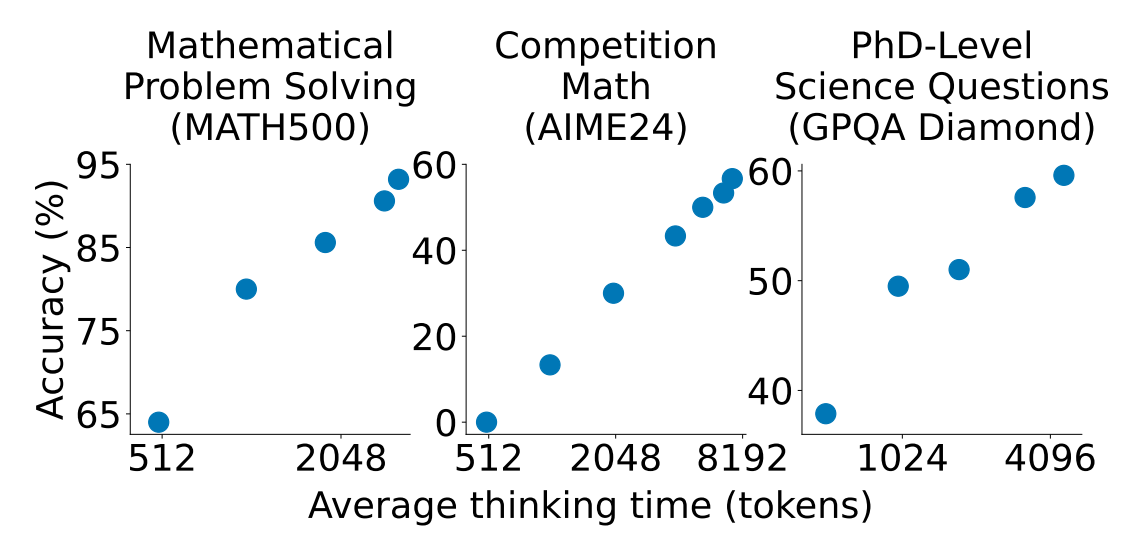
ตัว S1 ใช้เทคนิคที่เรียกว่า 'test-time scaling' ซึ่งทำให้การให้ความสามารถในการให้เหตุผลระหว่างการทำ inference ดีขึ้นโดยการให้ทรัพยากรในการคำนวณที่มากขึ้นตอนที่โมเดลสร้างคำตอบ วิธีนี้จะตรงข้ามกับการทำ LLM Model แบบทั่วไป เพราะจะใช้ทรัพยากรจำนวนมากตอนสร้างโมเดลในการเพิ่มประสิทธิภาพ และนอกจากนั้นตัว S1 จะใช้เทคนิคที่เรียกว่า 'Budget Forcing' ซึ่งโมเดลถูก prompt ให้ใช้กระบวนตรรกะ (reasoning) โดยการเติมคำว่า รอ (Wait) ในคำตอบ เพื่อใหตัวโมเดลตรวจงานตัวเองและแก้คำตอบก่อนส่งออกให้ผู้ใช้งาน

ใน Paper มีการอธิบายไว้ประมาณนี้ ถ้าใช้คำถามยอดฮิตที่ LLM ผิดบ่อย: “How many ‘r’s are in ‘raspberry’?”
การใช้เหตุผลตั้งต้น: โมเดลก็จะนับตัว r ไปทีละตัว เช่น เจอ r ตัวแรกก็จะนับ 1 และไล่ไปเรื่อยๆ ซึ่งระหว่างทางมันข้ามบางตัวไป จนไปเจอ r ตัวที่ 7 ก็จะนับ 2 และหยุดทุกงานที่ตัวที่ 8 ซึ่งจะได้คำตอบว่ามีตัว r 2 ตัวซึ่งเป็นคำตอบที่ผิด (คำตอบที่ถูกต้องคือ 3)
หลังจากนั้นตัว Budget forcing ก็จะเริ่มทำงาน ตัวระบบส่งสัญญาณให้หยุดโดยเพิ่มคำว่า รอ "Wait"เข้าไปที่ท้ายประโยคการให้เหตุผล ซึ่งทำให้โมเดลคิดใหม่ ตัวโมเดลก็ทำการตรวจสอบคำตอบอีกครั้ง และเพิ่ม r ที่หายไปเข้าไป เป็น 3 ตัวก่อนจะตอบกลับ
โดยการทำให้ตัวโมเดลตรวจสอบอีกครั้ง และแก้ไขตัวเอง ช่วยทำให้ความถูกต้องมากขึ้น ซึ่งก็เป็นกระบวนการที่เริ่มเห็นในโมเดลอื่นๆ ในการตรวจสอบตัวเองเช่นกัน ซึ่งเทคนิคนี้ทำให้โมเดลได้คะแนนดีขึ้นกว่า 20% ในโมเดลคณิตศาสตร์และวิทยาศาสตร์ ซึ่งมีบางกรณีตัวโมเดลถูกบังคับให้คิดใหม่ 16 ครั้ง จากที่ได้คะแนน 0 คะแนนในคำถามที่ยากๆ ทำให้โมเดลสามารถได้คะแนน 60% ได้ การคิดมากขึ้นทำให้มันแพงขึ้นแน่นอน แต่ถ้าเทคนิคนี้สามารถทำให้การสอนโมเดลตอนแรกถูกลงก็อาจจะเป็นวิธีที่คุ้มค่าขึ้นครับ
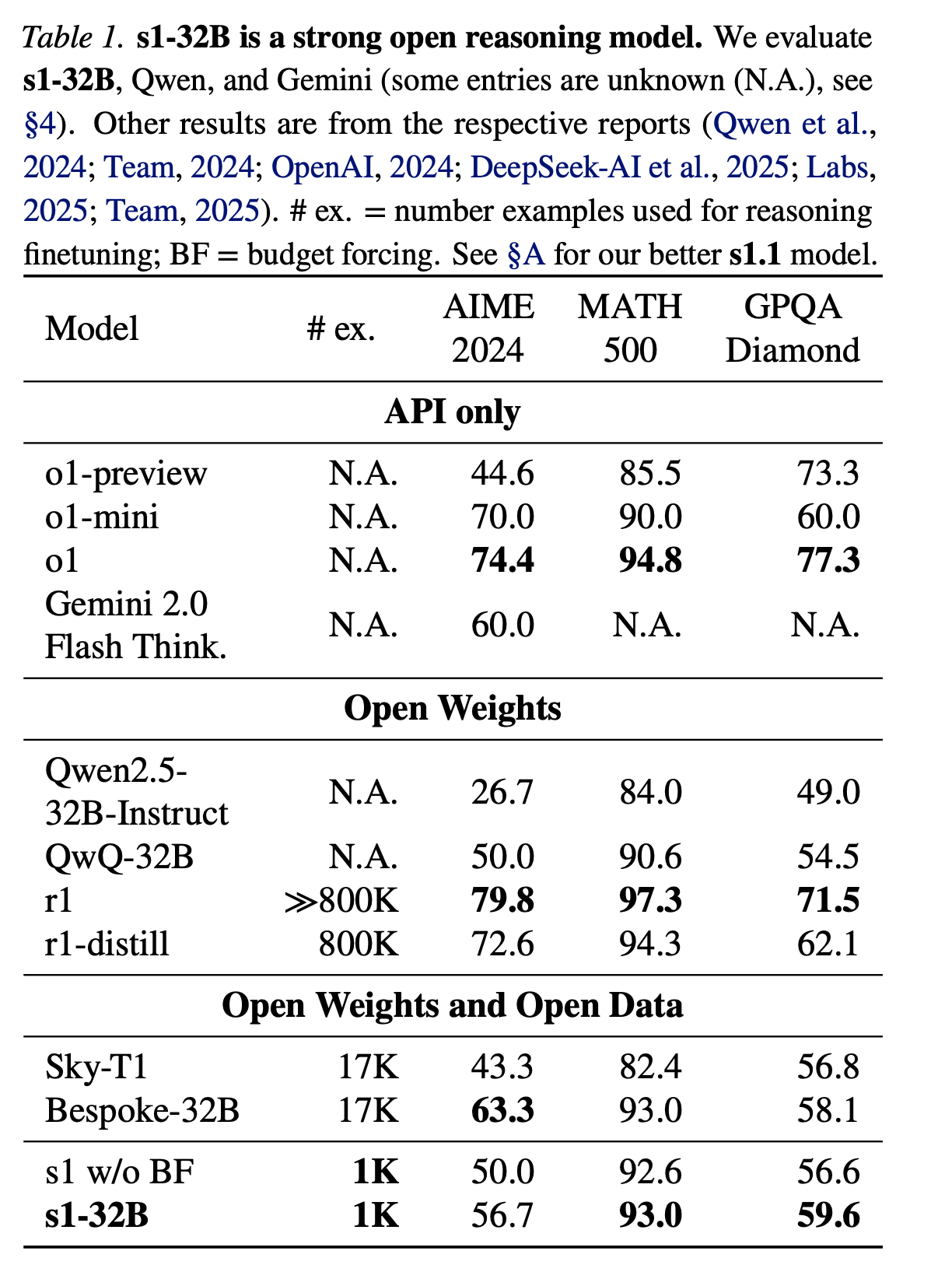
โดย S1 ก็ยังไม่ได้เก่งเท่า o1 หรือ o1-mini ด้วยซ้ำ แต่ในภาพใหญ่สามารถเอาชนะ o1-preview และ Sky-T1 โดยได้คะแนนเยอะกว่า QWQ-32B ในการทดสอบ AIME และ MATH และทำคะแนนได้ดีกว่า Bespoke-32B สำหรับการทดสอบ GPQA
ซึ่งคิดว่าเราจะเริ่มเห็นการสร้าง LLM ที่ถูกลงมากๆ โดยการใช้เทคนิคใหม่ๆ ต่างๆ แบบนี้กับ LLM ในอนาคตครับ ซึ่ง Use case ต่างๆ ก็น่าจะถูกลงเรื่อยๆ ครับ
References:
- https://arxiv.org/abs/2501.19393